尚硅谷Java技术之深圳高频面试题:第一章 Java基础
尚硅谷Java技术之深圳高频面试题
版本:V1.0
尚硅谷Java技术中心
第一章 Java基础
1. 谈一谈你对HashMap的理解
HashMap是一个Java中一个键值对容器(集合),是Map接口的一个具体实现,底层是用哈希表实现,在JDK1.7之前是数组+链表,JDK1.8之后,是数组+链表+红黑树,当链表长度大于8,数组长度大于64时会转化为红黑树。
2. 你说HashMap底层是 数组+链表+红黑树,为什么要用这几类结构呢?
数组 Node<K,V>[] table
,哈希表,根据对象的key的hash值进行在数组里面是哪个节点
链表的作用是解决hash冲突,将hash值取模之后的对象存在一个链表放在hash值对应的槽位
红黑树
JDK8使用红黑树来替代超过8个节点的链表,主要是查询性能的提升,从原来的O(n)到O(logn),
通过hash碰撞,让HashMap不断产生碰撞,那么相同的key的位置的链表就会不断增长,当对这个Hashmap的相应位置进行查询的时候,就会循环遍历这个超级大的链表,性能就会下降,所以改用红黑树
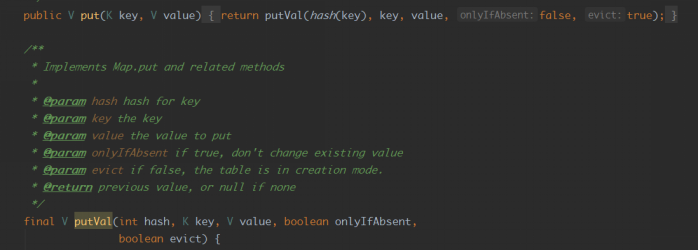
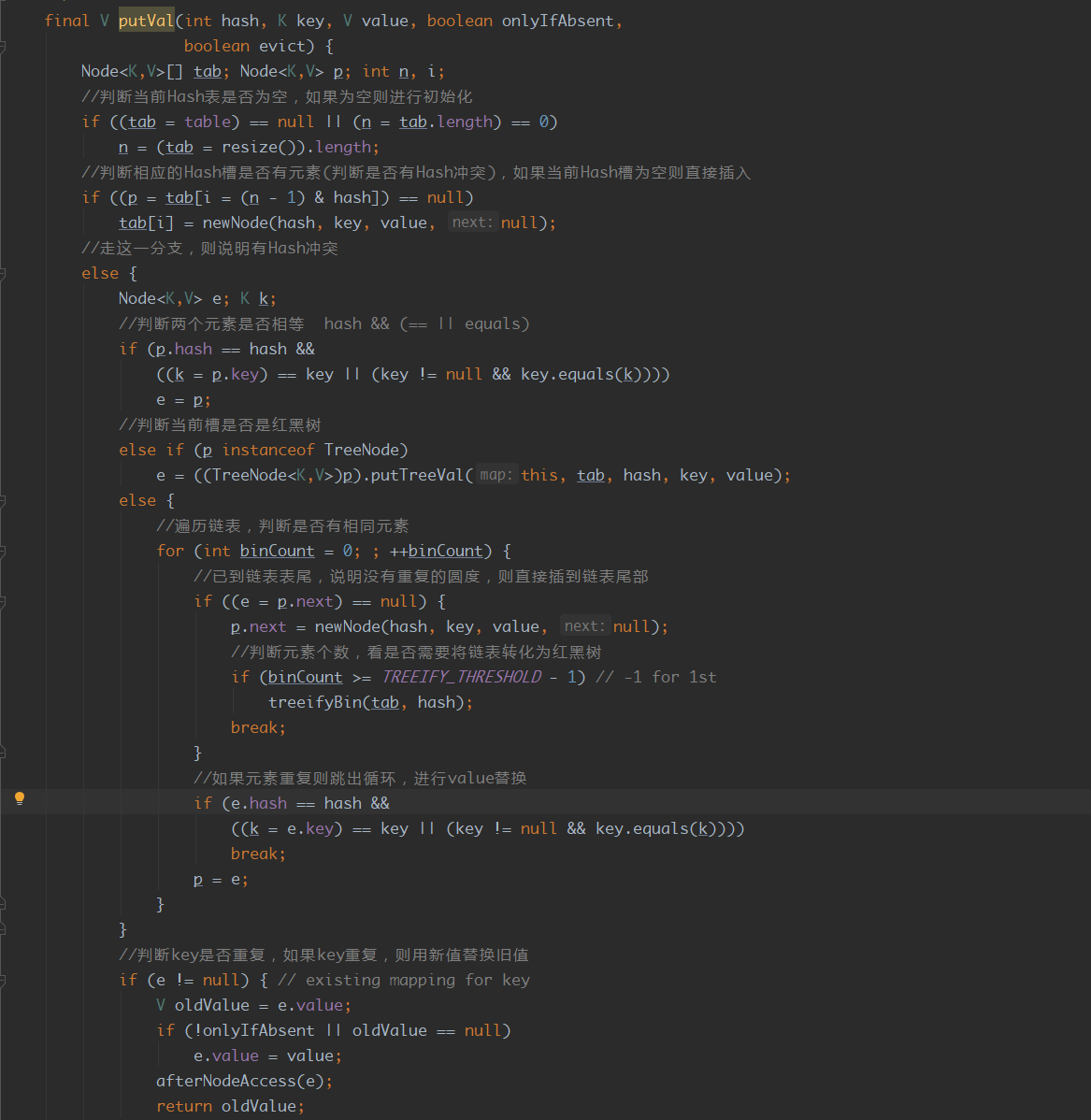
3. HashMap的put的流程
4. 了解ConcurrentHashMap吗?为什么性能比hashtable高,说下原理
ConcurrentHashMap是线程安全的Map容器,JDK8之前,ConcurrentHashMap使用锁分段技术,将数据分成一段段存储,每个数据段配置一把锁,即segment类,这个类继承ReentrantLock来保证线程安全,JKD8的版本取消Segment这个分段锁数据结构,底层也是使用Node数组+链表+红黑树,从而实现对每一段数据就行加锁,也减少了并发冲突的概率。
hashtable类基本上所有的方法都是采用synchronized进行线程安全控制,高并发情况下效率就降低
,ConcurrentHashMap是采用了分段锁的思想提高性能,锁粒度更细化
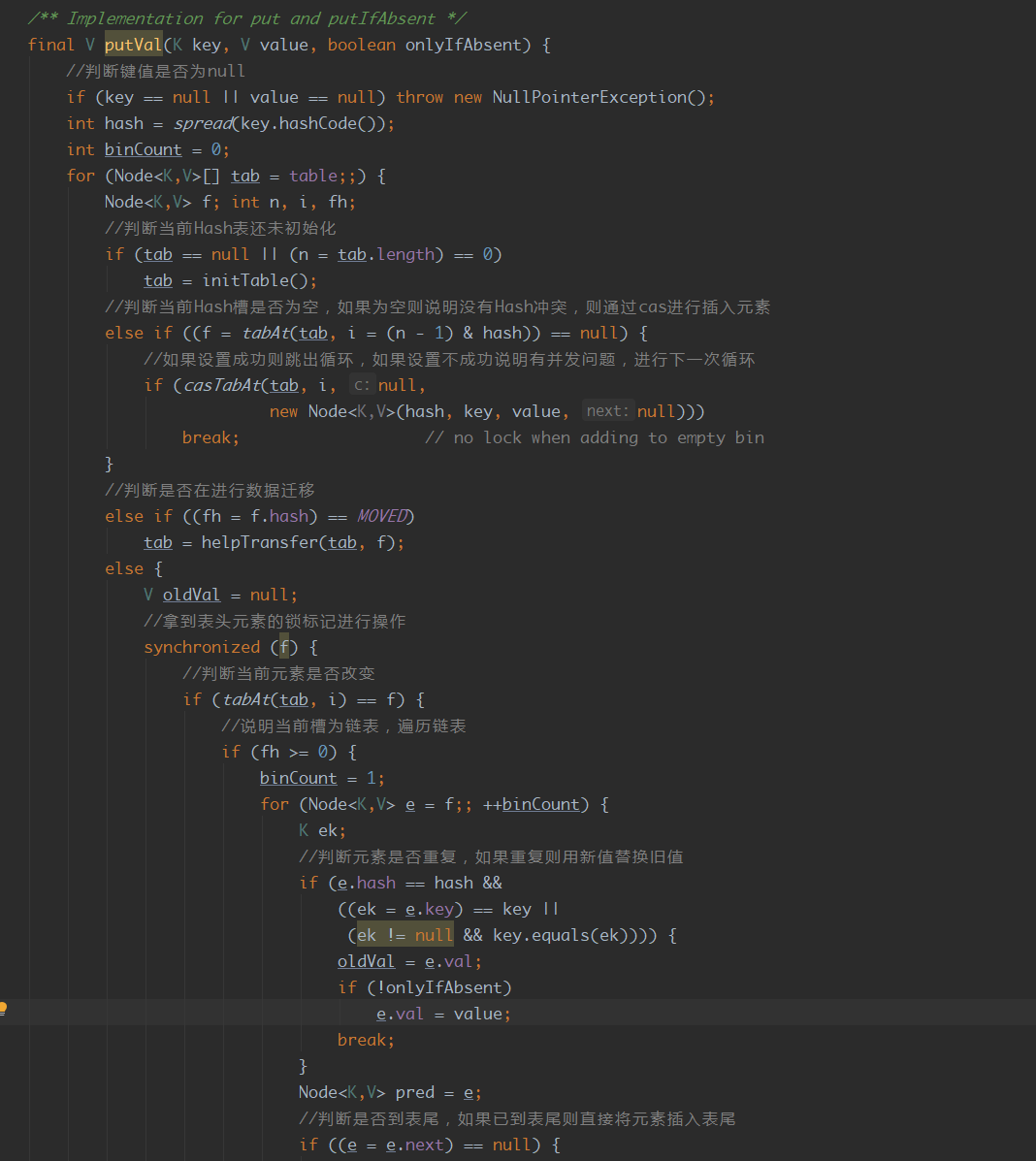
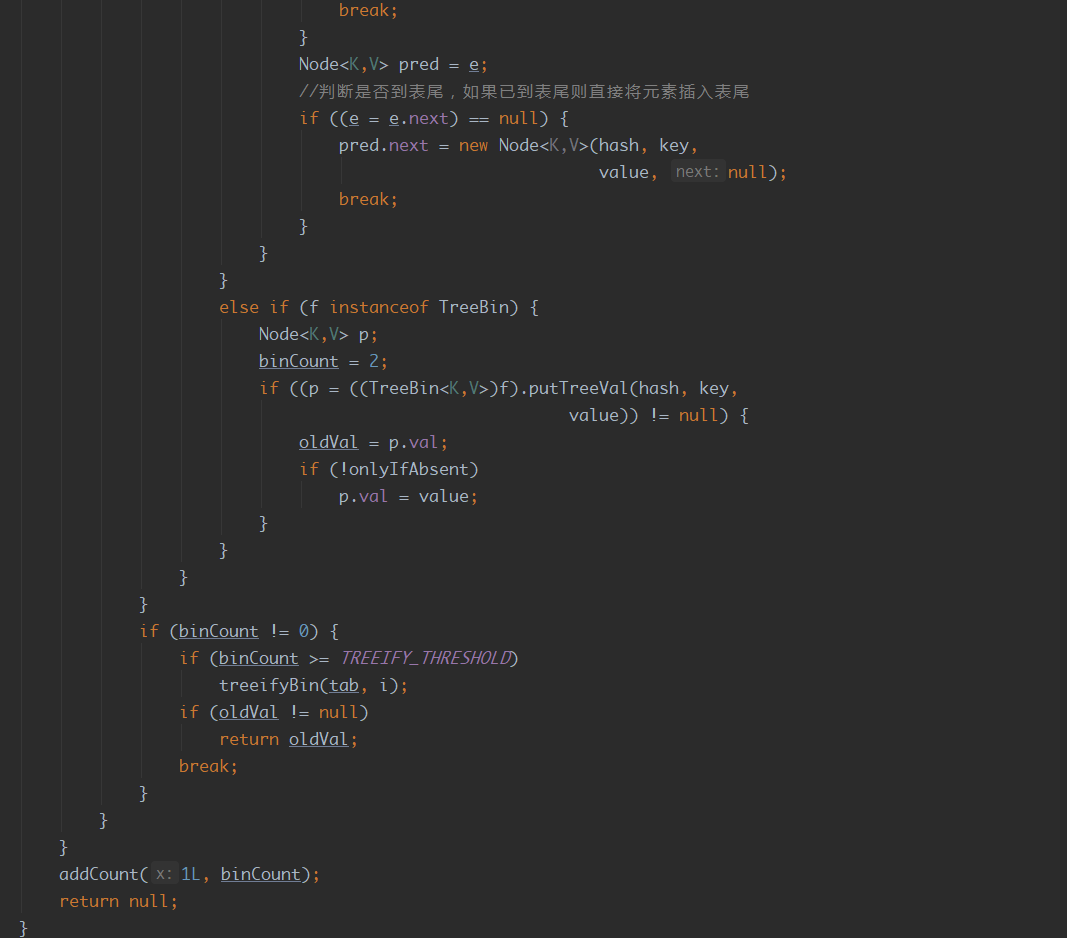
5. ConcurrentHashMap的put流程

6. ArrayList和LinkedList的区别
(1)ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
(2)对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
(3)对于新增和删除操作add和remove,LinkedList比较占优势,因为ArrayList要移动数据。这一点要看实际情况的。若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。但若是批量随机的插入删除数据,LinkedList的速度大大优于ArrayList.
因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。
7. StringBuffer和StringBuilder的区别
(1)StringBuffer 与StringBuilder 中的方法和功能完全是等价的。
(2)只是StringBuffer
中的方法大都采用了synchronized关键字进行修饰,因此是线程安全的,而StringBuilder
没有这个修饰,可以被认为是线程不安全的。(3)在单线程程序下,StringBuilder效率更快,因为它不需要加锁,不具备多线程安全而StringBuffer则每次都需要判断锁,效率相对更低。
8. 线程的创建方式
1)继承Thread类创建线程
2)实现Runnable接口创建线程
3)使用Callable和Future创建线程
4)使用线程池创建线程
9. 线程池的创建方式
在JDK 的java.util.concurrent.Executors
中提供了生成多种线程池的静态方法。
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
ExecutorService newFixedThreadPool = Executors.newFixedThreadPool(4);
ScheduledExecutorServicenewScheduledThreadPool=
Executors.newScheduledThreadPool(4);
ExecutorService newSingleThreadExecutor =
Executors.newSingleThreadExecutor();
这4种线程池底层全部是ThreadPoolExecutor对象的实现,在实际开发中,我们使用线程池也会自己创建ThreadPoolExecutor实例,阿里规范手册中也规定线程池采用ThreadPoolExecutor进行自定义。
10. 线程池的工作流程
1、如果正在运行的线程数量小于
corePoolSize,那么马上创建线程运行这个任务
2、如果正在运行的线程数量大于或等于
corePoolSize,那么将这个任务放入队列
3、如果这时候队列满了,而且正在运行的线程数量小于
maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务
4、如果队列满了,而且正在运行的线程数量大于或等于
maximumPoolSize,那么线程池会抛出异常RejectExecutionException
11. 在生产环境中,你们线程池的核心线程数和最大线程数是怎么设置的?
1.需要分析线程池执行的任务的特性:CPU 密集型还是IO 密集型
2.每个任务执行的平均时长大概是多少,这个任务的执行时长可能还跟任务处理逻辑是否涉及到网络传输以及底层系统资源依赖有关系
如果是CPU 密集型,主要是执行计算任务,响应时间很快,cpu
一直在运行,这种任务cpu的利用率很高,那么线程数的配置应该根据CPU
核心数来决定,CPU 核心数=最大同时执行线程数,加入CPU
核心数为4,那么服务器最多能同时执行4
个线程。过多的线程会导致上下文切换反而使得效率降低。那线程池的最大线程数可以配置为cpu
核心数+1 如果是IO 密集型,主要是进行IO 操作,执行IO
操作的时间较长,这是cpu 出于空闲状态,导致cpu
的利用率不高,这种情况下可以增加线程池的大小。这种情况下可以结合线程的等待时长来做判断,等待时间越高,那么线程数也相对越多。一般可以配置cpu
核心数的2 倍。
一个公式:线程池设定最佳线程数目= ((线程池设定的线程等待时间+线程CPU
时间)/线程CPU 时间)* CPU 数目
这个公式的线程cpu 时间是预估的程序单个线程在cpu
上运行的时间(通常使用loadrunner测试大量运行次数求出平均值)
线程池相关知识可以参考链接:https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html,讲的很全面
12. 你是怎么理解反射的?
(1)反射机制:所谓的反射机制就是java语言在运行时拥有一项自观的能力。通过这种能力可以彻底的了解自身的情况为下一步的动作做准备。
Java的反射机制的实现要借助于4个类:class,Constructor,Field,Method;
其中class代表的时类对象,Constructor-类的构造器对象,Field-类的属性对象,Method-类的方法对象。通过这四个对象我们可以粗略的看到一个类的各个组成部分。
(2)Java反射的作用:在Java运行时环境中,对于任意一个类,可以知道这个类有哪些属性和方法。对于任意一个对象,可以调用它的任意一个方法。这种动态获取类的信息以及动态调用对象的方法的功能来自于Java
语言的反射(Reflection)机制。
(3)Java 反射机制提供功能在运行时判断任意一个对象所属的类。
在运行时构造任意一个类的对象。
在运行时判断任意一个类所具有的成员变量和方法。
在运行时调用任意一个对象的方法
相关文章:
第一章 Java基础
第二章 MySQL相关
第三章 框架相关
第四章 Redis相关
第五章 JVM相关
第六章 消息队列相关
第七章 项目相关
真诚点赞 诚不我欺~
{{ praiseUserVoList.length }}人点赞
内容
"{{ child.parent.content }}"