尚硅谷Java技术之上海高频面试题:第四章 MySQL数据库篇
尚硅谷Java技术之上海高频面试题
版本:V1.0
尚硅谷Java技术中心
第四章 MySQL数据库篇
1、数据库的存储引擎有哪些,有什么区别?
| 引擎名称 | 特点 |
|---|---|
| innoDB | 数据库默认的存储引擎 被设计用来处理大数据量的短期事务,除非有特别的要求,否则我们使用默认即可 |
| myisam | 1,主要体现的功能storage(存储); 2,对事务安全性要求不高 读多写少 常被用于设计日志记录表; 3,不支持事务,意味着存储效率高,但是文件一旦丢失,将无法恢复。 |
| ARCHIVE | 档案存储引擎,只支持 insert 与select 操作 |
| BLACKH OLE 黑洞 | 1,没有实现任何的存储机制 它会丢失所有插入的数据,不做任何存储;2,但是服务器会记录blackhole的日志;3,可以用于复制数据到备份数据库或者简单的日志记录 |
| csv | 1,可以将普通的csv格式的文件作为mysql的表来处理;2,不支持所有,可以作为一种数据交换的机制而存在 |
| memory | 1,存储到内存而非磁盘;2,常被用于临时表 (用完即删);3,如果需要快速访问数据, 并且这些数据不会被修改,重启以后丢失也没有关系,可以使用该存储引擎 |
2、有没有设计过数据表?你是如何设计的?

聚簇索引与非聚簇索引有什么区别
都是B+树的数据结构
聚簇索引:将数据存储与索引放到了一块、并且是按照一定的顺序组织的,找到索引也就找到了数据,数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的
非聚簇索引叶子节点不存储数据、存储的是数据行地址,也就是说根据索引查找到数据行的位置再取磁盘查找数据,这个就有点类似一本书的目录,比如我们要找第三章第一节,那我们先在这个目录里面找,找到对应的页码后再去对应的页码看文章。
优势:
1、查询通过聚簇索引可以直接获取数据,相比非聚簇索引需要第二次查询(非覆盖索引的情况下)效率要高
2、聚簇索引对于范围查询的效率很高,因为其数据是按照大小排列的
3、聚簇索引适合用在排序的场合,非聚簇索引不适合
劣势;
1、维护索引很昂贵,特别是插入新行或者主键被更新导至要分页(pagesplit)的时候。建议在大量插入新行后,选在负载较低的时间段,通过OPTIMIZETABLE优化表,因为必须被移动的行数据可能造成碎片。使用独享表空间可以弱化碎片
2、表因为使用uuId(随机ID)作为主键,使数据存储稀疏,这就会出现聚簇索引有可能有比全表扫面更慢,所以建议使用int的auto_increment作为主键
3、如果主键比较大的话,那辅助索引将会变的更大,因为辅助索引的叶子存储的是主键值,过长的主键值,会导致非叶子节点占用占用更多的物理空间
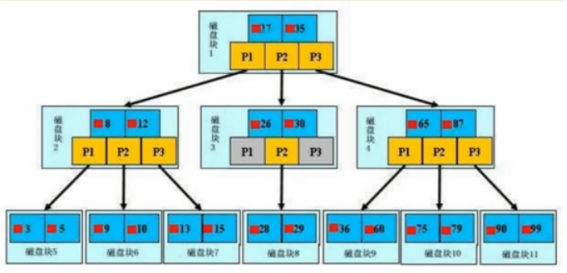
B+tree 与 B-tree区别
原理:分批次的将磁盘块加载进内存中进行检索,若查到数据,则直接返回,若查不到,则释放内存,并重新加载同等数据量的索引进内存,重新遍历
结构: 数据 向下的指针 指向数据的指针
特点:
1,节点排序
2 .一个节点了可以存多个元索,多个元索也排序了
结构: 数据 向下的指针
特点:
1.拥有B树的特点
2.叶子节点之间有指针
3.非叶子节点上的元素在叶子节点上都冗余了,也就是叶子节点中存储了所有的元素,并且排好顺序
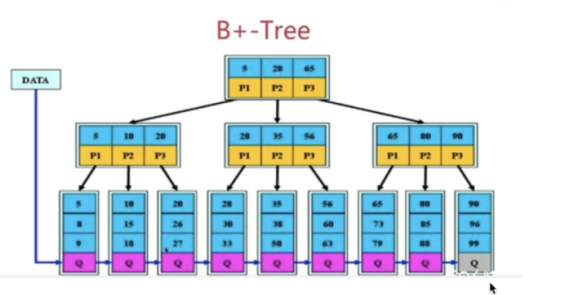
从结构上看,B+Tree 相较于 B-Tree 而言
缺少了指向数据的指针 也就红色小方块;
Mysq|索引使用的是B+树,因为索引是用来加快查询的,而B+树通过对数据进行排序所以是可以提高查询速度的,然后通过一个节点中可以存储多个元素,从而可以使得B+树的高度不会太高,在Mysql中一个Innodb页就是一个B+树节点,一个Innodb页默认16kb,所以一般情况下一颗两层的B+树可以存2000万行左右的数据,然后通过利用B+树叶子节点存储了所有数据并且进行了排序,并且叶子节点之间有指针,可以很好的支持全表扫描,范围查找等SQL语句
5、以mysql为例 linux如何排查问题?
类似提问方式:如果线上环境出现问题比如网站卡顿重则瘫痪 如何是好?
—>linux—>mysql/redis/nacos/sentinel/sluth—>可以从以上提到的技术点中选择一个自己熟悉单技术点进行分析
以mysql为例
1,架构层面 是否使用主从
2,表结构层面
是否满足常规的表设计规范(大量冗余字段会导致查询会变得很复杂)
3,sql语句层面(⭐)
前提:由于慢查询日志记录默认是关闭的,所以开启数据库mysql的慢查询记录
的功能 从慢查询日志中去获取哪些sql语句时慢查询 默认10S
,从中获取到sql语句进行分析
3.1 explain 分析一条sql
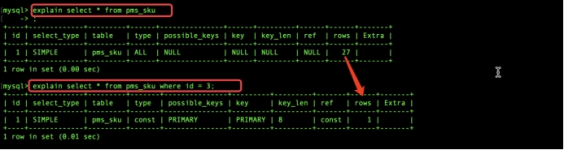
Id:执行顺序 如果单表的话,无参考价值 如果是关联查询,会据此判断主表 从表
Select_type:simple
Table:表
Type: ALL 未创建索引 、const、 常量ref其他索引 、eq_ref 主键索引、
Possible_keys
Key 实际是到到索引到字段
Key_len 索引字段数据结构所使用长度 与是否有默认值null
以及对应字段到数据类型有关,有一个理论值 有一个实际使用值也即key_len的值
Rows 检索的行数 与查询返回的行数无关
Extra 常见的值:usingfilesort 使用磁盘排序算法进行排序,事关排序 分组
的字段是否使用索引的核心参考值
还可能这样去提问:sql语句中哪些位置适合建索引/索引建立在哪个位置
Select id,name,age from user where id=1 and name=“xxx” order by age
总结: 查询字段 查询条件(最常用) 排序/分组字段
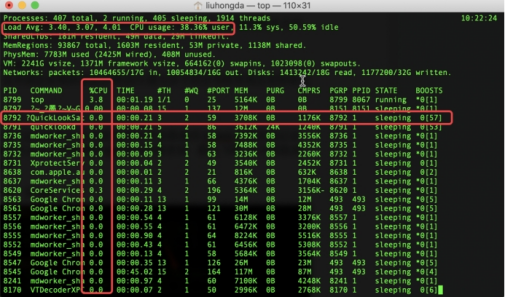
补充:如何判断是数据库的问题?可以借助于top命令
如何处理慢查询
在业务系统中,除了使用主键进行的查询,其他的都会在测试库上测试其耗时,慢查询的统计主要由运维在做,会定期将业务中的慢查询反馈给我们。
慢查询的优化首先要搞明白慢的原因是什么?是查询条件没有命中索引?是加载了不需要的数据列?还是数据量太大?
所以优化也是针对这三个方向来的
首先分析语句,看看是否加载了额外的数据,可能是查询了多余的行并且抛弃掉了,可能是加载了许多结果中并不需要的列,对语句进行分析以及重写。
分析语句的执行计划,然后获得其使用索引的情况,之后修改语句或者修改索引,使得语句可以尽可能的命中索引。
如果对语句的优化已经无法进行,可以考虑表中的数据量是否太大,如果是的话可以进行横向或者纵向的分表。
相关文章:
第一章 面试技巧篇
第一章 Java基础
第三章 Java高级篇
第四章 MySQL数据库篇
第五章 Java框架篇
第六章 Redis数据库篇
第七章 MQ消息队列
第八章 电商项目篇之谷粒商城
真诚点赞 诚不我欺~
{{ praiseUserVoList.length }}人点赞
内容
"{{ child.parent.content }}"