尚硅谷Java技术之上海高频面试题:第五章 Java框架篇
尚硅谷Java技术之上海高频面试题
版本:V1.0
尚硅谷Java技术中心
第五章 Java框架篇
1、简单的谈一下SpringMVC的工作流程?
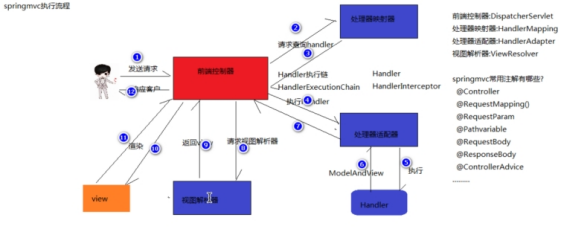
1、用户向服务器发送请求,请求被SpringMVC的前端控制器DispatcherServlet截获。
2、DispatcherServlet对请求的URL(统一资源定位符)进行解析,得到URI(请求资源标识符),然后根据该URI,调用HandlerMapping获得该Handler配置的所有相关的对象,包括Handler对象以及Handler对象对应的拦截器,这些对象都会被封装到一个HandlerExecutionChain对象当中返回。
3、DispatcherServlet根据获得的Handler,选择一个合适的HandlerAdapter。HandlerAdapter的设计符合面向对象中的单一职责原则,代码结构清晰,便于维护,最为重要的是,代码的可复制性高。HandlerAdapter会被用于处理多种Handler,调用Handler实际处理请求的方法。
4、提取请求中的模型数据,开始执行Handler(Controller)。在填充Handler的入参过程中,根据配置,spring将帮助做一些额外的工作
消息转换:将请求的消息,如json、xml等数据转换成一个对象,将对象转换为指定的响应信息。
数据转换:对请求消息进行数据转换,如String转换成Integer、Double等。
数据格式化:对请求的消息进行数据格式化,如将字符串转换为格式化数字或格式化日期等。
数据验证:验证数据的有效性如长度、格式等,验证结果存储到BindingResult或Error中。
5、Handler执行完成后,向DispatcherServlet返回一个ModelAndView对象,ModelAndView对象中应该包含视图名或视图模型。
6、根据返回的ModelAndView对象,选择一个合适的ViewResolver(视图解析器)返回给DispatcherServlet。
7、ViewResolver结合Model和View来渲染视图。
8、将视图渲染结果返回给客户端。
以上8个步骤,DispatcherServlet、HandlerMapping、HandlerAdapter和ViewResolver等对象协同工作,完成SpringMVC请求—>响应的整个工作流程,这些对象完成的工作对于开发者来说都是不可见的,开发者并不需要关心这些对象是如何工作的,开发者,只需要在Handler(Controller)当中完成对请求的业务处理。
2、Spring循环依赖
常见问法
请解释一下spring中的三级缓存
三级缓存分别是什么?三个Map有什么异同?
什么是循环依赖?请你谈谈?看过spring源码吗?
如何检测是否存在循环依赖?实际开发中见过循环依赖的异常吗?
多例的情况下,循环依赖问题为什么无法解决?
什么是循环依赖?
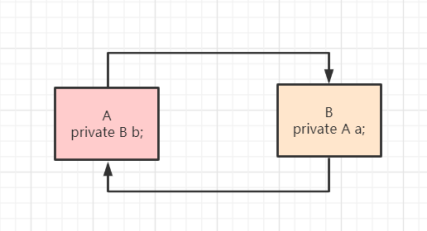
两种注入方式对循环依赖的影响?
官方解释
相关概念
实例化:堆内存中申请空间

初始化:对象属性赋值

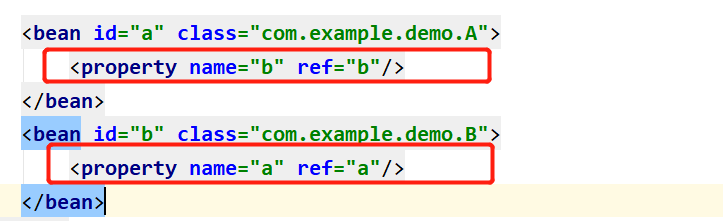
三级缓存
一级缓存 singletonObjects 存放已经经历了完整生命周期的Bean对象
二级缓存 earlySingletonObjects 存放早期暴露出来的Bean对象,Bean的生命周期未结束(属性还未填充完)
三级缓存 singletonFactories 存放可以生成Bean的工厂
四个关键方法

package org.springframework.beans.factory.support;
...
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry {
...
/**
单例对象的缓存:bean名称—bean实例,即:所谓的单例池。
表示已经经历了完整生命周期的Bean对象
第一级缓存
*/
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/**
早期的单例对象的高速缓存: bean名称—bean实例。
表示 Bean的生命周期还没走完(Bean的属性还未填充)就把这个 Bean存入该缓存中也就是实例化但未初始化的 bean放入该缓存里
第二级缓存
*/
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
/**
单例工厂的高速缓存:bean名称—ObjectFactory
表示存放生成 bean的工厂
第三级缓存
*/
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
}
debug源代码过程
需要22个断点(可选)
1,A创建过程中需要B,于是A将自己放到三级缓里面,去实例化B
2,B实例化的时候发现需要A,于是B先查一级缓存,没有,再查二级缓存,还是没有,再查三级缓存,找到了A然后把三级缓存里面的这个A放到二级缓存里面,并删除三级缓存里面的A
3,B顺利初始化完毕,将自己放到一级缓存里面(此时B里面的A依然是创建中状态)
然后回来接着创建A,此时B已经创建结束,直接从一级缓存里面拿到B,然后完成创建,并将A自己放到一级缓存里面。
总结
1,Spring创建
bean主要分为两个步骤,创建原始bean对象,接着去填充对象属性和初始化。
2,每次创建
bean之前,我们都会从缓存中查下有没有该bean,因为是单例,只能有一个。
3,当创建
A的原始对象后,并把它放到三级缓存中,接下来就该填充对象属性了,这时候发现依赖了B,接着就又去创建B,同样的流程,创建完B填充属性时又发现它依赖了A又是同样的流程,不同的是:这时候可以在三级缓存中查到刚放进去的原始对象A。
所以不需要继续创建,用它注入 B,完成 B的创建既然 B创建好了,所以
A就可以完成填充属性的步骤了,接着执行剩下的逻辑,闭环完成
Spring解决循环依赖依靠的是Bean的"中间态"这个概念,而这个中间态指的是已经实例化但还没初始化的状态—>半成品。实例化的过程又是通过构造器创建的,如果A还没创建好出来怎么可能提前曝光,所以构造器的循环依赖无法解决
其他衍生问题
问题1:为什么构造器注入属性无法解决循环依赖问题?
由于spring中的bean的创建过程为先实例化
再初始化(在进行对象实例化的过程中不必赋值)将实例化好的对象暴露出去,供其他对象调用,然而使用构造器注入,必须要使用构造器完成对象的初始化的操作,就会陷入死循环的状态
问题2:一级缓存能不能解决循环依赖问题? 不能
在三个级别的缓存中存储的对象是有区别的
一级缓存为完全实例化且初始化的对象 二级缓存实例化但未初始化对象
如果只有一级缓存,如果是并发操作下,就有可能取到实例化但未初始化的对象,就会出现问题
问题3:二级缓存能不能解决循环依赖问题?
理论上二级缓存可以解决循环依赖问题,但是需要注意,为什么需要在三级缓存中存储匿名内部类(ObjectFactory),原因在于
需要创建代理对象 eg:现有A类,需要生成代理对象 A是否需要进行实例化(需要)
在三级缓存中存放的是生成具体对象的一个匿名内部类,该类可能是代理类也可能是普通的对象,而使用三级缓存可以保证无论是否需要是代理对象,都可以保证使用的是同一个对象,而不会出现,一会儿使用普通bean
一会儿使用代理类
3、简述SpringBoot自动装配原理
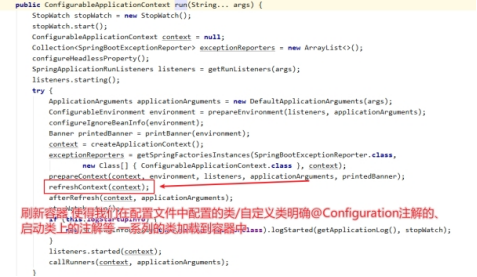
第一个关键点:run方法底层原码有一个方法如下图
第二个关键点:启动类注解@SpringBootApplication
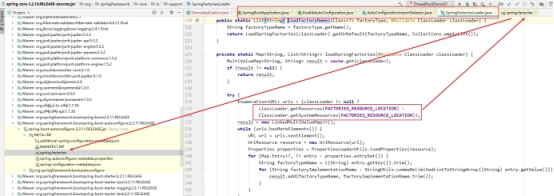
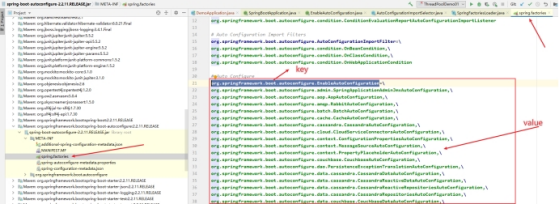
以redis为例
1,引入依赖规范 spring-boot-starter-data-XXX

2,springboot是如何通过场景启动器进行加载的?
设计springboot加载核心技术点:自动装配 AutoConfiguration

总结:
Springboot在启动的时候会调用run方法,run方法会执行refreshContext()方法刷新容器,会在类路径下找到springboot-boot-autoconfigure/springboot-boot-autoconfigure.jar/META-INF/spring-factories文件,该文件中记录中众多的自动配置类,容器会根据我们是否引入依赖是否书写配置文件的情况,将满足条件的Bean注入到容器中,于是就实现了springboot的自动装配
MyBatis中 #{}和${}的区别是什么?
#{}是预编译处理,${}是字符串替换;
Mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值;
Mybatis在处理${}时,就是把${}替换成变量的值;
使用#{}可以有效的防止SQL注入,提高系统安全性。
谈谈你对Spring 的理解
Spring 是一个开源框架,为简化企业级应用开发而生。Spring可以是使简单的JavaBean 实现以前只有EJB 才能实现的功能。Spring 是一个 IOC和 AOP 容器框架。
Spring 容器的主要核心是:
控制反转(IOC),传统的 java开发模式中,当需要一个对象时,我们会自己使用 new 或者 getInstance等直接或者间接调用构造方法创建一个对象。而在 spring 开发模式中,spring容器使用了工厂模式为我们创建了所需要的对象,不需要我们自己创建了,直接调用spring提供的对象就可以了,这是控制反转的思想。
依赖注入(DI),spring 使用 javaBean 对象的 set方法或者带参数的构造方法为我们在创建所需对象时将其属性自动设置所需要的值的过程,就是依赖注入的思想。
面向切面编程(AOP),在面向对象编程(oop)思想中,我们将事物纵向抽成一个个的对象。而在面向切面编程中,我们将一个个的对象某些类似的方面横向抽成一个切面,对这个切面进行一些如权限控制、事物管理,记录日志等公用操作处理的过程就是面向切面编程的思想。AOP底层是动态代理,如果是接口采用 JDK 动态代理,如果是类采用CGLIB方式实现动态代理。
5、Spring中常用的设计模式
(1)代理模式------spring
中两种代理方式,若目标对象实现了若干接口,spring 使用jdk
的java.lang.reflect.Proxy类代理。若目标兑现没有实现任何接口,spring 使用
CGLIB 库生成目标类的子类。
(2)单例模式------在 spring 的配置文件中设置 bean 默认为单例模式。
(3)模板方式模式------用来解决代码重复的问题。
比如:RestTemplate、JmsTemplate、JpaTemplate
(4)工厂模式------在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用同一个接口来指向新创建的对象。Spring
中使用 beanFactory 来创建对象的实例。
6、介绍一下Spring bean 的生命周期、注入方式和作用域
Bean的生命周期
(1)默认情况下,IOC容器中bean的生命周期分为五个阶段:
-
调用构造器 或者是通过工厂的方式创建Bean对象
-
给bean对象的属性注入值
-
调用初始化方法,进行初始化,初始化方法是通过init-method来指定的.
-
使用
-
IOC容器关闭时, 销毁Bean对象.
(2)当加入了Bean的后置处理器后,IOC容器中bean的生命周期分为七个阶段:
-
调用构造器 或者是通过工厂的方式创建Bean对象
-
给bean对象的属性注入值
-
执行Bean后置处理器中的 postProcessBeforeInitialization
-
调用初始化方法,进行初始化, 初始化方法是通过init-method来指定的.
-
执行Bean的后置处理器中 postProcessAfterInitialization
-
使用
-
IOC容器关闭时, 销毁Bean对象
只需要回答出第一点即可,第二点也回答可适当 加分。
注入方式:
通过 setter 方法注入
通过构造方法注入
Bean的作用域
总共有四种作用域:
-
Singleton 单例的
-
Prototype 原型的
-
Request
-
Session
相关文章:
第一章 面试技巧篇
第一章 Java基础
第三章 Java高级篇
第四章 MySQL数据库篇
第五章 Java框架篇
第六章 Redis数据库篇
第七章 MQ消息队列
第八章 电商项目篇之谷粒商城
真诚点赞 诚不我欺~
{{ praiseUserVoList.length }}人点赞
内容
"{{ child.parent.content }}"